

Engineering researchers have developed a hybrid machine-learning approach to muscle gesture recognition in prosthetic hands that combines an AI technique normally used for image recognition with another approach specialized for handwriting and speech recognition. The technique is achieving far superior performance than traditional machine learning efforts.
A paper describing the hybrid approach was published in the journal Cyborg and Bionic Systems.
Motor neurons are those parts of the central nervous system that directly control our muscles. They transmit electrical signals that cause muscles to contract. Electromyography (EMG) is a method of measuring muscle response by recording this electrical activity through the insertion of electrode needles through the skin and into the muscle. Surface EMG (sEMG) performs this same recording process in a non-invasive fashion with the electrodes placed on the skin above the muscle, and is used for non-medical procedures such as sports and physiotherapy research.
Over the last decade, researchers have begun investigating the potential use of surface EMG signals to control prostheses for amputees, especially with respect to the complexity of movements and gestures required by prosthetic hands in order to deliver smoother, more responsive, and more intuitive activity of the devices than is currently possible.
Unfortunately, unexpected environmental interference such as a shift of the electrodes introduces a great deal of ‘noise’ to the process of any device attempting to recognize the surface EMG signals. Such shifts regularly occur in daily wear and use of such systems. To try to overcome this problem, users must engage in a lengthy and tiring sEMG signal training period prior to use of their prostheses. Users are required to laboriously collect and classify their own surface EMG signals in order to be able to control the prosthetic hand.
In order to reduce or eliminate the challenges of such training, researchers have explored various machine learning approaches—in particular deep learning pattern recognition—to be able to distinguish between different, complex hand gestures and movements despite the presence of environmental signal interference.
A reduction in the training is in turn obtained by optimizing the network structure model of that deep learning. One possible improvement that has been trialed is the use of a convolutional neural network (CNN), which is analogous to the connection structure of the human visual cortex. This type of neural network offers improved performance with images and speech and as such is at the heart of computer vision.
Researchers up to now have achieved some success with CNN, significantly improving upon the recognition (‘extraction’) of the spatial dimensions of sEMG signals related to hand gestures. But while good dealing with space, they struggle with time. Gestures are not static phenomena, but take place over time, and CNN ignores time information in the continuous contraction of muscles.
Recently, some researchers have begun to apply a long short-term memory (LSTM) artificial neural network architecture to the problem. LSTM involves a structure that involves ‘feedback’ connections, giving it superior performance in processing classifying, and making predictions based on sequences of data over time, especially where there are lulls, gaps or interferences of unexpected duration between the events that are important. LSTM is a form of deep learning that has been best applied to tasks that involve unsegmented, connected activity such as handwriting and speech recognition.
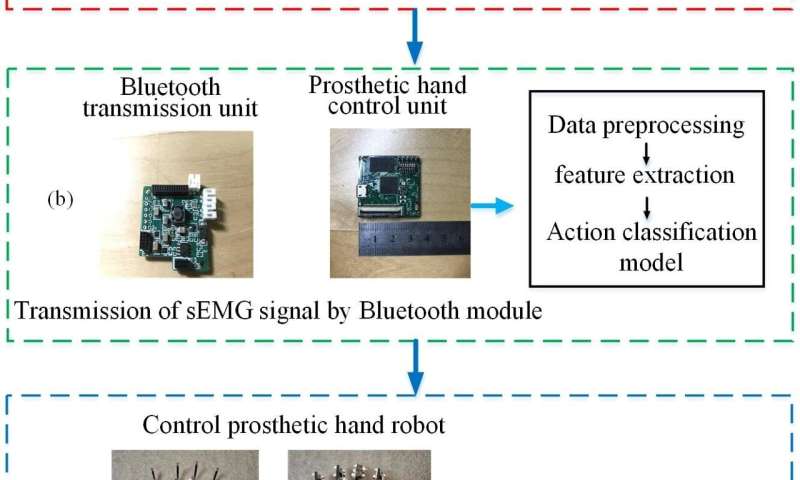
The challenge here is that while researchers have achieved better gesture classification of sEMG signals, the size of the computational model required is a serious problem. The microprocessor needed to be used is limited. Using something more powerful would be too costly. And finally, while such deep learning training models work with the computers in the lab, they are difficult to apply via the sort of embedded hardware found in a prosthetic device
“Convolutional neural networks were after all conceived with image recognition in mind, not control of prostheses,” said Dianchun Bai, one of the authors of the paper and professor of electrical engineering at Shenyang University of Technology. “We needed to couple CNN with a technique that could deal with the dimension of time, while also ensuring feasibility in the physical device that the user must wear.”
So the researchers developed a hybrid CNN and LSTM model that combined the spacial and temporal advantages of the two approaches. This reduced the size of the deep learning model while achieving high accuracy, with more robust resistance to interference.

After developing their system, they tested the hybrid approach on ten non-amputee subjects engaging in a series of 16 different gestures such as gripping a phone, holding a pen, pointing, pinching and grasping a cup of water. The results demonstrated far superior performance compared to CNN alone or other traditional machine learning methods, achieving a recognition accuracy of over 80 percent.
The hybrid approach did however struggle to accurately recognize two pinching gestures: a pinch using the middle finger and one using the index finger. In future efforts, the researchers want to optimize the algorithm and improve its accuracy still further, while keeping the training model small so it can be used in prosthesis hardware. They also want to figure out what is prompting the difficulty in recognizing pinching gestures and expand their experiments to a much larger number of subjects.
Source: Read Full Article